




Mniej więcej rok temu otrzymałem mail z Biblioteki Narodowej z pytaniem, czy nie chciałbym wziąć udziału w testach nowej aplikacji pomagającej w wyszukiwaniu i gromadzeniu informacji. Pewnie, czemu nie?
Projekt nosi nazwę mLUMEN i w ogólnym zarysie ma stanowić rodzaj agregatu treści, obejmującego książki, publikacje, treści udostępniane przez instytucje publiczne, a także artykuły z portali oraz stron internetowych. Jako, że ktoś w Bibliotece Narodowej uznał Kwantowo za blog o “wysokiej jakości zamieszczanych treści”[1], zaproponowano mi włączenie tutejszych wpisów już do wczesnej wersji aplikacji, a tym samym do wzięcia udziału w testach. Słowo ciałem się stało i niedawno poinformowano mnie, że wersja beta mLUMEN jest już dostępna.
Jednak zanim ocenię dotychczasowe starania twórców, kilka słów o przyświecającej im idei. Z tego, co rozumiem, chodzi o połączenie funkcjonalności wyszukiwarki wertującej zasoby polskich bibliotek (Omnis, Polona) z bazą statystyk, wykazów, list i raportów udostępnianych w serwisie dane.gov.pl oraz zasobami stron internetowych. Te ostatnie docelowo będą mogły przystępować do systemu, poprzez instalację i konfigurację odpowiedniej wtyczki Lumen-WP (ale na razie jej nie szukajcie, bo jeszcze nie weszła do użytku). Wszystkie dane z tych różnych źródeł mają być mielone i sortowane na podstawie automatycznie nadawanych tagów tematycznych.
Oczywiście zerkając w tym momencie pod adres mlumen.bn.org.pl, należy mieć na uwadze, że jest to wciąż plac budowy i właściwie każda z dostępnych opcji na pewno zostanie poprawiona i rozbudowana. Zakładki Obserwowane tematy, Do przeczytania oraz Tematy na czasie, sugerują jednak już teraz, że aplikacja ma być nie tylko wyszukiwarką, ale działać również, jako narzędzie służące do agregowania, porządkowania i monitorowania interesujących nas wątków.
Ma to sens, zwłaszcza przez pomysł zaangażowaniu w projekt twórców internetowych, którzy – w przyszłości, po dołączeniu do bazy większej liczby stron – będą regularnie dostarczać aktualnych artykułów i newsów z poszczególnych dziedzin. Po założeniu konta możemy np. zaobserwować tag “mechanika kwantowa” i widzieć zarówno to, co oferują nam biblioteki (zwykłe i cyfrowe), jak i świeży tekst Kwantowo lub innej witryny. Niby nic nowego (pewnie mało kto pamięta, że dawno temu istniał prosty agregator naukowych treści, skupiający większość polskich blogów tematycznych), ale przy odpowiednim rozmachu, taki zbiornik może okazać się bardzo użyteczny.
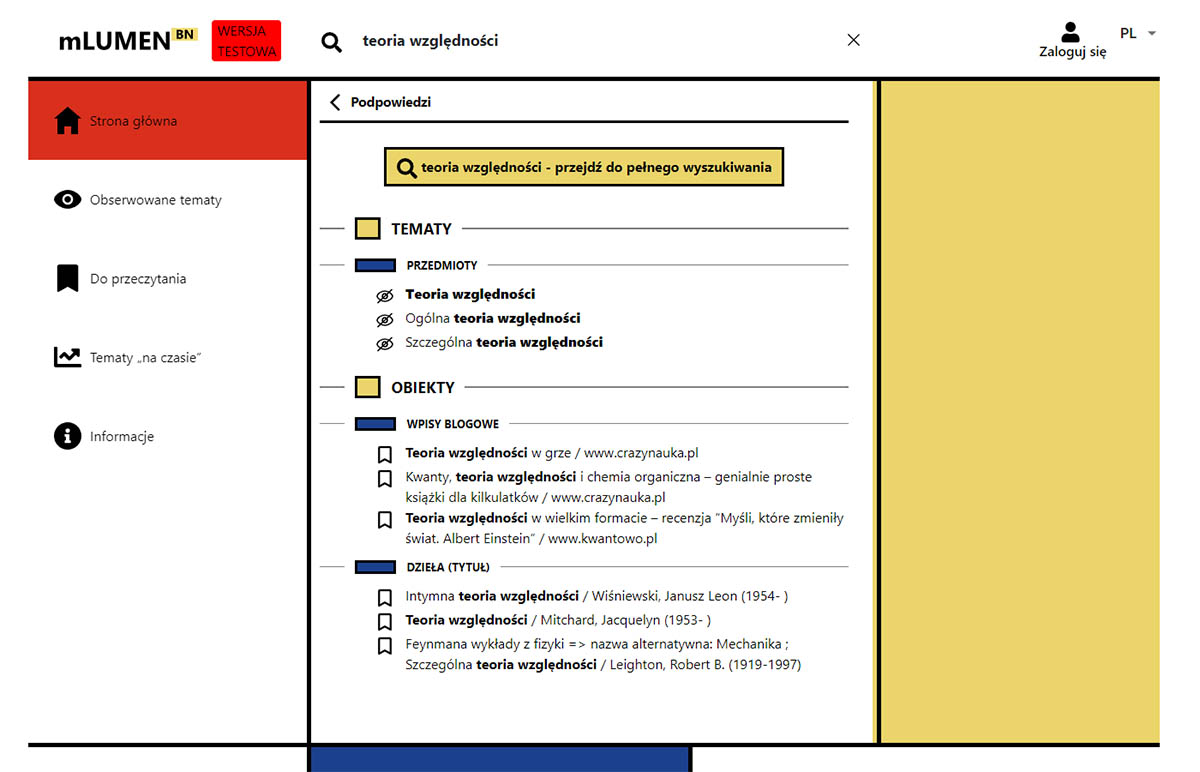
Jednak do pełnej funkcjonalności, jeszcze trochę aplikacji brakuje. Obserwowanie tematów nadal nie działa jak należy (przynajmniej kiedy ja sprawdzałem), a wyszukiwarka wydaje się dość niezdarna. Przykładowo, po wstukaniu hasła “ogólna teoria względności” nie zobaczę namiaru na artykuł pt. Najpiękniejsza weryfikacja ogólnej teorii względności, bo szukajka najwyraźniej nie radzi sobie z odmianą słów i prawdopodobnie nie zagląda poniżej tytułu. Sam tekst widnieje w bazie, ale co dziwne system przyporządkował mu tagi przestrzeń kosmiczna, badania naukowe, fizyka, Stany Zjednoczone (?), ale już nie teoria względności.
Mam też pewną, bardziej ogólną wątpliwość. Obecnie mLUMEN gromadzi w tym momencie zasoby jedynie stron zaproszonych do współpracy, jednak po udostępnieniu wtyczki, do projektu będzie mógł przystąpić każdy. Z jednej strony, to dobrze, bo wolność słowa i większy zasób tekstów; z drugiej taka decyzja może w łatwy sposób zmienić agregat w śmietnisko. Czy będzie istniała metoda na odsianie treści nienaukowych i fejknewsów? Czy powstanie system zgłaszania podejrzanych treści? Czy, poza rozwiązaniami technicznymi, aplikację będą doglądać ludzcy moderatorzy? Mam nadzieję, że tak.
Pozostaje trzymać kciuki za dalszy rozwój projektu. Poruszamy się w rzeczywistości chaosu informacyjnego, a każda szeroka próba uporządkowania tego rozgardiaszu zasługuje na uwagę. I to nie tylko pracowników naukowych i studentów, ślęczących akurat nad pracą dyplomową – ale również zwykłych użytkowników internetu.
